Google DeepMind has released Gemma, a series of open models inspired by the same research and technology used for Gemini. This article summarized the main parts of paper Gemma: Open Models Based on Gemini Research and Technology and shown the basic way for running this model on local devices. Then give a conclusion on this model.
Main Contents:
- First Impression on Gemma
- Model Architecture
- Training Data
- Performance on Public Test Data
- Running Gemma 2B and 7B
- Conclusion
First Impression on Gemma
Google DeepMind has released Gemma, a series of open models inspired by the same research and technology used for Gemini. The open model lends itself to a variety of use cases, which is a very smart move by Google. There are 2B (trained on 2T tokens) and 7B (trained on 6T tokens) models, including base and instruction-tuned versions. Training is performed on a context length of 8192 tokens. Commercial use permitted. These are not multimodal models and are superior to Llama 2 7B and Mistral 7B based on reported experimental results.
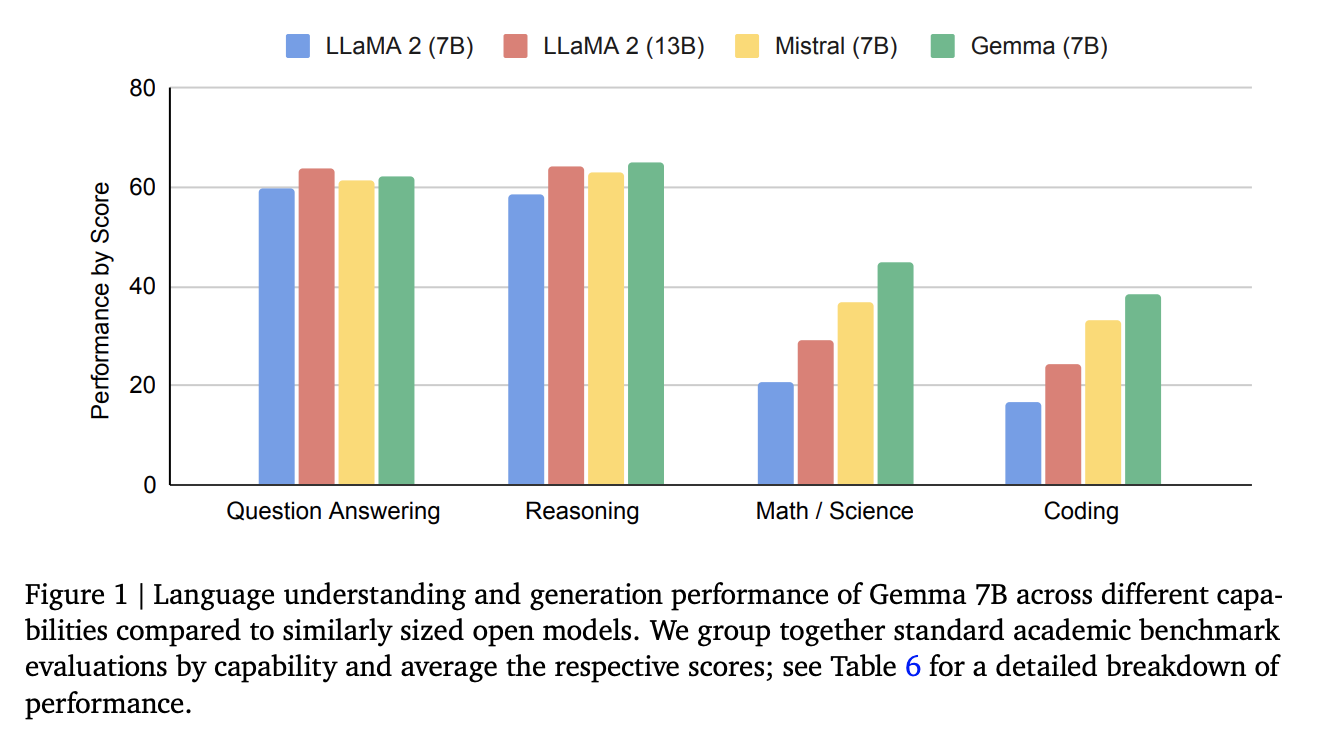
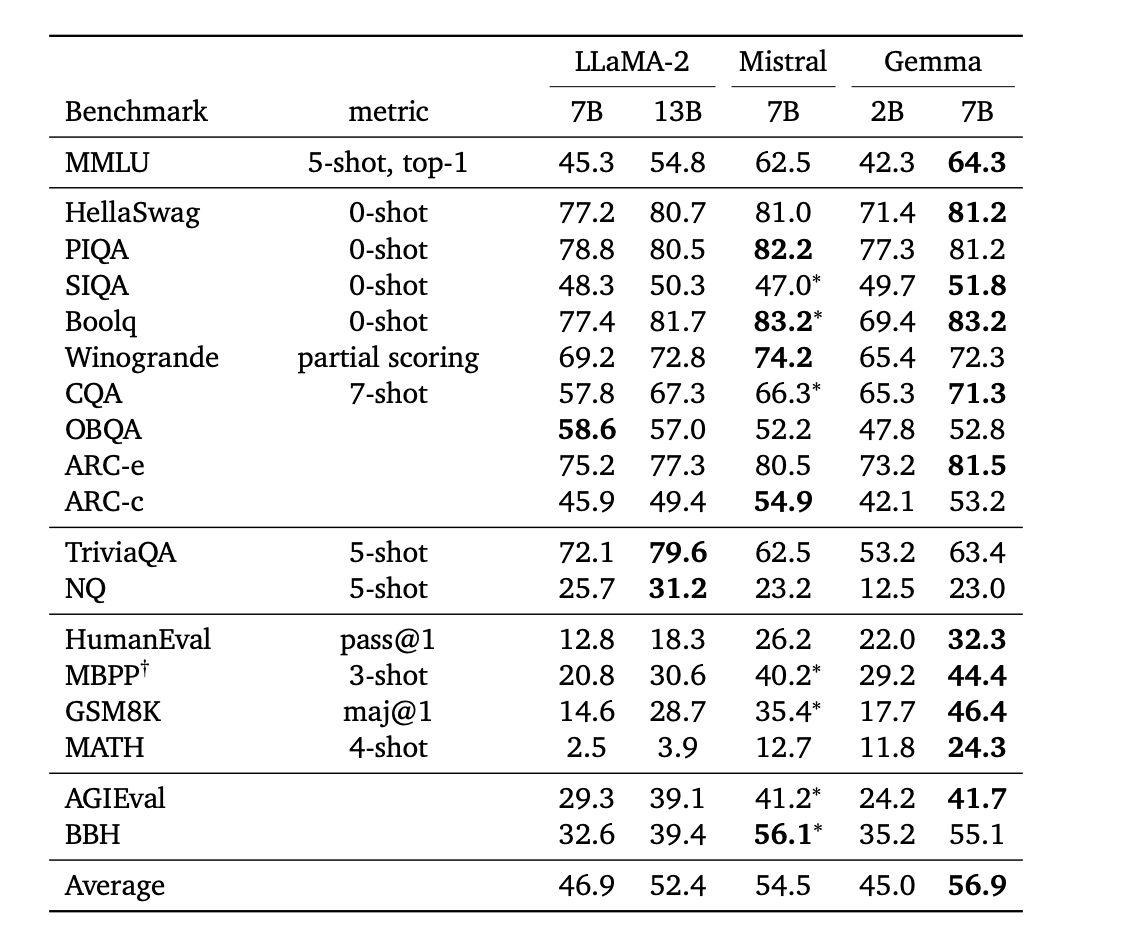
Gemma models improve performance in a wide range of domains including conversation, reasoning, mathematics, and code generation. The results of MMLU (64.3%) and MBPP (44.4%) not only demonstrate the high performance of Gemma, but also show that there is still room for improvement in the performance of open and available large models.
Gemma draws on many experiences from the Gemini model project, including code, data, architecture, instruction tuning, reinforcement learning from human feedback, and evaluation.
Model Architecture
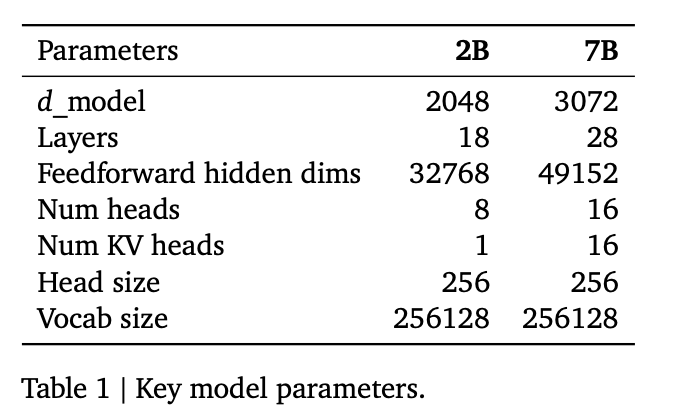
The Gemma model architecture is a transformer-based decoder. The core parameters of the architecture are summarized in Table 1 below. The model is trained on a context length of 8192 tokens. We also take advantage of several improvements proposed since the original transformer paper. Below we list the included improvements:
Multi-Query Attention: The 7B model uses multi-query attention, while the 2B checkpoint uses multi-query attention (num_kv_heads=1). Based on the ablation study results, the respective attention variants are at their respective scales Improved performance.
RoPE Embeddings: Instead of using absolute position embeddings, rotational position embeddings are used in each layer; in order to reduce model size, embeddings are also shared between input and output.
GeGLU Activations: The standard ReLU nonlinearity is replaced by the GeGLU activation function.
Normalizer Location: Normalizes both the input and output of each transformer sublayer, deviating from the standard practice of normalizing only one of them. Use RMSNorm as the normalization layer.
Training Data
Gemma2B and 7B are trained on 2T and 6T of main English web document, mathematics and code data respectively. Unlike Gemini, these models are neither multimodal nor trained for optimal performance on multilingual tasks. For compatibility, a subset of the Gemini SentencePiece tokenizer is used. It splits numbers without removing extra whitespace, and relies on byte-level encoding to handle unknown tokens, following techniques used by (Chowdhery et al., 2022) and (Gemini Team, 2023). The vocabulary size is 256k tokens.
Since the vocabulary is very large, the model needs to be trained longer to better learn embeddings for all tokens in the vocabulary. The loss should still decrease after expanding the training tokens, which also corresponds to the very large vocabulary. We can understand that the larger the vocabulary, the more training tokens may be needed, and of course the performance may be better.
For the instruction version of the model, they performed supervised fine-tuning on an instruction dataset consisting of human and synthetic data, followed by reinforcement learning with human feedback (RLHF).

Performance on public test data
Running Gemma 2B and 7B
Hugging Face's Transformers and vLLM already support the Gemma model, and the hardware requirement is an 18gb GPU.
Let’s first introduce vLLM
1 | import time |
Transformers then
1 | import torch |
Conclusion
Many frameworks already support Gemma models well, and quantization of GPTQ and AWQ will be released soon. After quantization, Gemma 7B can be used on 8gb GPU.
It is undeniable that releasing the Gemma model is a step forward for Google. Gemma 7B looks like a good competitor to Mistral 7B, but let's not forget that it also has 1 billion more parameters than Mistral 7B. In addition, I have never figured out what the use cases of Gemma 2B are. Its performance is surpassed by other models of similar size (this 2B may be really 2B), and it can be seen that the performance of these two Google models with few parameters is not good, but the performance is good. There are many more parameters. This kind of word play shows that Google is indeed lagging behind and anxious on the AI track, and there is currently no way to surpass it.
Here is the gemma-report officially released by Google. If you are interested, you can check it out.
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf